🗺️ Visão geral do fluxo: Condutor → Executor → Crítico
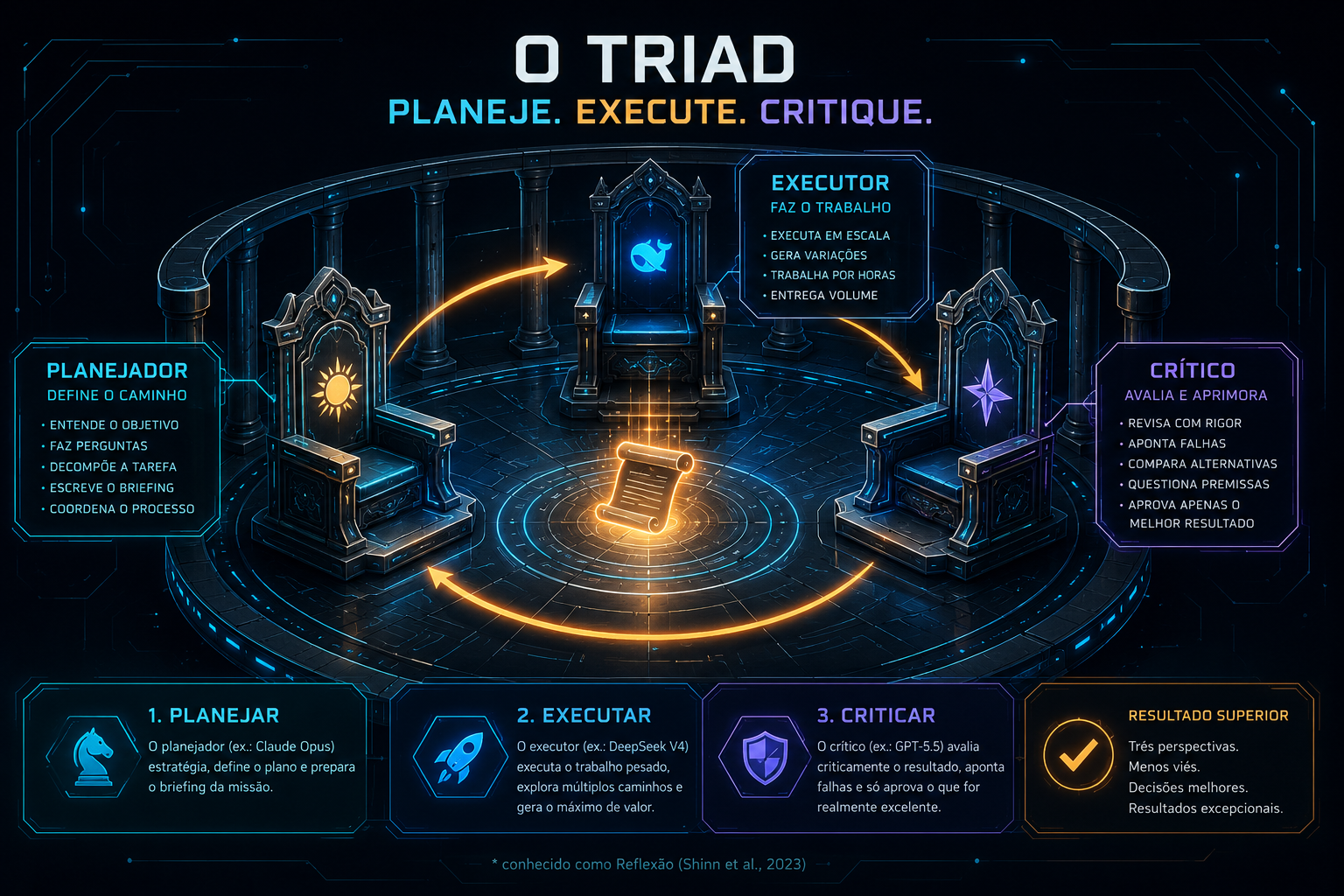
O Triad é um sistema de três papéis distintos executados por três modelos diferentes. Cada papel resolve um problema que os outros não conseguem resolver sozinhos — e a separação é o que produz resultado verificado em vez de output plausível.
O que é
Um pipeline com três etapas obrigatórias: o Condutor (Opus) transforma o objetivo em briefing preciso; o Executor (DeepSeek) explora múltiplos ângulos em paralelo; o Crítico (GPT-5.5) avalia cada draft contra os critérios do briefing e emite SHIP, REVISE ou FUNDAMENTAL FLAW. O loop Executor↔Crítico roda até SHIP, e o Condutor faz a validação final.
🔗 O fluxo, ponta a ponta
Usuário
│ objetivo bruto
▼
┌─────────────────────────┐
│ CONDUTOR (Opus) │ interroga, briefa, valida
└─────────────────────────┘
│ briefing estruturado
▼
┌─────────────────────────┐
│ EXECUTOR (DeepSeek) │ 3–5 ângulos em paralelo
└─────────────────────────┘
│ drafts ◄──────┐
▼ │ REVISE
┌─────────────────────────┐
│ CRÍTICO (GPT-5.5) │ SHIP / REVISE / FLAW
└─────────────────────────┘
│ SHIP
▼
CONDUTOR valida → entrega ao usuário
Pergunta o que falta, escreve o briefing, valida o output final contra o objetivo original.
Explora 3–5 ângulos em paralelo com premissas distintas. Volume e custo baixo.
Avalia cada ângulo contra os critérios. Emite veredicto específico, não opinião.
🔑 Conceitos-chave
Cada modelo resolve um problema que os outros não resolvem sozinhos
A ordem Condutor → Executor → Crítico → Validação é fixa
Executor e Crítico iteram entre si até SHIP — o usuário não participa
O Condutor revisa o SHIP do Crítico antes de entregar — duplo controle
🎙️ Opus como Condutor — interrogar, briefar, validar
O Condutor é o único papel que conversa com o usuário. Claude Opus é escolhido aqui porque seu forte é raciocínio estruturado — ele interroga até entender, escreve um briefing testável, e valida o resultado final contra o objetivo original.
O que é
O modelo de planejamento — Claude Opus opera como gerente de projeto. Recebe o pedido do usuário (geralmente vago), faz perguntas até eliminar ambiguidade, produz um briefing estruturado com critérios mensuráveis, e no final do loop revisa o output entregue pelo Crítico antes de devolver ao usuário.
📝 Estrutura de um briefing do Condutor
# BRIEFING
OBJETIVO: [uma frase, sem ambiguidade]
CRITÉRIOS DE SUCESSO:
- [testável #1]
- [testável #2]
- [testável #3]
RESTRIÇÕES:
- [o que NÃO fazer]
- [formatos inaceitáveis]
CONTEXTO: [dados que o Executor não tem]
ÂNGULOS SUGERIDOS:
1. [premissa A]
2. [premissa B — fundamentalmente diferente de A]
3. [premissa C]
✗ Sem Condutor
- ✗Usuário envia objetivo vago direto ao Executor
- ✗Crítico avalia sem critérios — vira opinião
- ✗Loop diverge: SHIP em coisa errada
- ✗Resultado plausível, não verificado
✓ Com Condutor
- ✓Briefing elimina ambiguidade antes da execução
- ✓Crítico tem critérios objetivos para julgar
- ✓Loop converge: SHIP é alinhado ao objetivo
- ✓Validação final confirma encaixe com o pedido
💡 Por que Opus aqui
Opus tem o melhor raciocínio passo-a-passo da família Anthropic. Ele consegue (a) detectar lacunas no pedido inicial, (b) formular perguntas que reduzem ambiguidade, (c) sintetizar respostas em critérios testáveis. Esses três passos definem se o resto do Triad vai produzir algo útil ou apenas plausível.
🔑 Conceitos-chave
O Condutor pergunta antes de despachar — não assume
O briefing é o contrato que o Crítico usa para julgar
Mesmo após SHIP do Crítico, o Condutor revisa o encaixe
O usuário só fala com o Condutor — Executor e Crítico ficam encapsulados
⚙️ DeepSeek como Executor — volume, custo, resiliência
O Executor produz volume — 3–5 ângulos por iteração, e potencialmente dezenas de iterações até SHIP. DeepSeek é escolhido aqui porque combina capacidade de raciocínio com custo baixo o suficiente para rodar por horas sem inviabilizar a operação.
O que é
O modelo de execução — DeepSeek opera como força de trabalho do Triad. Lê o briefing, gera múltiplos ângulos com premissas diferentes, recebe feedback do Crítico, revisa e ressubmete. Pode rodar continuamente por horas em tarefas grandes sem que o custo se torne proibitivo.
DeepSeek — Executor
Opus — Condutor
GPT-5.5 — Crítico
🛠️ Por que DeepSeek aqui
- •Custo 17× menor que Opus: permite gerar 17× mais drafts pelo mesmo orçamento — viabiliza paralelismo real.
- •Janela de contexto longa: aguenta briefings densos sem perder o início.
- •Arquitetura MoE: ativa apenas os experts relevantes por token, mantendo latência baixa em iterações longas.
- •Resiliência operacional: roda por horas sem rate limit estourar — ideal para tarefas com 10+ iterações.
💡 Princípio do executor "barato"
O Executor é o papel que mais consome tokens — porque é quem produz volume. Usar o modelo mais caro aqui inverteria a economia do Triad. Você quer o modelo mais barato que ainda consiga raciocinar — não o modelo mais inteligente disponível.
🔑 Conceitos-chave
Gerar volume é mais importante que gerar perfeição na primeira tentativa
17× mais barato que Opus permite 10+ iterações sem inviabilizar a operação
Mixture of Experts ativa só o necessário — bom para iterações longas
Sustenta tarefas multi-hora sem interrupção
🔍 GPT-5.5 como Crítico — rigor, especificidade, aprovação
O Crítico é o portão de qualidade. GPT-5.5 é escolhido aqui porque tem o melhor desempenho em detectar premissas implícitas e falhas lógicas finas — exatamente o que diferencia uma resposta plausível de uma resposta correta.
O que é
O modelo de revisão — GPT-5.5 recebe o briefing e cada draft do Executor, e emite um de três veredictos: SHIP (atende todos os critérios), REVISE (problema localizado e corrigível), ou FUNDAMENTAL FLAW (a premissa do draft está errada — recomeçar). Cada veredicto vem com especificação do problema, localização no draft e direção da correção.
Todos os critérios do briefing foram atendidos. Encaminhar ao Condutor para validação final.
Problema específico e localizado. Executor revisa a parte indicada e ressubmete.
A premissa do draft está errada. Descartar e gerar novo ângulo com premissa diferente.
✗ Crítica vaga (rejeitada)
- ✗"Análise rasa, melhorar"
- ✗"Faltam exemplos"
- ✗"Resultado fraco"
- ✗"Refazer com mais profundidade"
✓ Crítica específica (válida)
- ✓"Ângulo 2 assume LTV ≥ 12 meses sem dado de retenção"
- ✓"Critério #3 (ticket ≥ $3k) não atendido no nicho A"
- ✓"Parágrafo 4 cita competidores sem preço — viola restrição"
- ✓"FUNDAMENTAL FLAW: ângulo 3 confunde causa e correlação"
📝 System prompt do Crítico (núcleo)
Você é o Crítico. Você NÃO escreve drafts.
Para cada draft recebido:
1. Liste cada critério do briefing
2. Marque ATENDIDO/NÃO-ATENDIDO/PREMISSA-INVÁLIDA
3. Emita veredicto: SHIP | REVISE | FUNDAMENTAL FLAW
4. Se REVISE: localize o trecho, descreva o gap,
proponha direção (NÃO escreva o conteúdo).
Proibido: "poderia ser melhor", "mais detalhado",
"mais profundo", "mais exemplos".
🔑 Conceitos-chave
SHIP, REVISE, FUNDAMENTAL FLAW — sem zona cinzenta intermediária
Aponta direção; reescrita é trabalho do Executor — separação de papéis
Onde, o quê, por que — sem isso o veredicto é inválido
REVISE corrige; FUNDAMENTAL FLAW recomeça — distinção crítica
🔁 O loop interno DeepSeek ↔ GPT — até o SHIP
Entre o briefing e o SHIP existe um loop fechado. O Executor produz, o Crítico julga, o Executor revisa — e essa iteração continua até que todos os critérios do briefing sejam atendidos. O usuário não vê esse loop; ele só recebe o resultado validado.
O que é
O ciclo de iteração entre Executor e Crítico. Começa quando o Executor recebe o briefing e termina quando o Crítico emite SHIP em todos os ângulos avaliados. Tarefas de complexidade média convergem em 2–3 iterações; tarefas com premissas instáveis podem precisar de 5+.
⏱️ Timeline de uma execução real
3 ângulos gerados. Ângulo 1: nicho clínicas odontológicas. Ângulo 2: SaaS para pequenos contadores. Ângulo 3: serviço de manutenção predial.
"Ângulo 1 assume ticket $3k+ sem dado. Ângulo 2 cita 3 competidores sem preço — viola restrição. Ângulo 3 sem urgência de compra documentada."
Ângulo 1 com dado de ticket médio (R$ 4.200, fonte CFO). Ângulo 2 com preço dos 3 competidores. Ângulo 3 reescrito com gatilho de urgência (multas ANVISA).
"Ângulo 1 e 3 OK. Ângulo 2: o preço citado é do plano básico — o critério #2 exige ticket médio efetivo. Recalcular com mix realista."
Ângulo 2 recalculado: mix 60% básico + 30% plus + 10% enterprise → ticket médio $3.180. Atende critério.
"Todos os 3 ângulos atendem aos 5 critérios do briefing. Encaminhar ao Condutor para validação final."
🎯 Benchmark de convergência
Tarefas de complexidade média devem convergir em 2–3 iterações. Acima de 5 iterações, suspeite do briefing — provavelmente um critério está mal formulado ou um ângulo precisa de inversão de premissa.
🔑 Conceitos-chave
Usuário fora; Executor e Crítico iteram sozinhos até SHIP
Cada iteração resolve um critério não atendido — progresso mensurável
5+ iterações é sinal de briefing fraco, não de executor ruim
Sem SHIP, nada chega ao Condutor — sem Condutor, nada chega ao usuário
🌈 Por que os modelos devem ser de arquiteturas diferentes
Se você usasse três instâncias do mesmo modelo, eles compartilhariam as mesmas cegueiras — premissas implícitas, padrões de raciocínio, vieses de treino. Arquiteturas diferentes pegam erros diferentes, e essa diversidade é o que torna o Triad mais que a soma das partes.
O que é
O princípio da diversidade arquitetural — combinar modelos que foram treinados com filosofias diferentes (Constitutional AI, RLHF + tools, MoE) para que as cegueiras de um sejam compensadas pelos fortes do outro. É a versão LLM da revisão por pares de disciplinas distintas.
Treinado com princípios constitucionais aplicados recursivamente. Forte em raciocínio estruturado, ético e em seguir instruções complexas.
Pega: ambiguidade, escopo, ética operacional
Treinado com RLHF intensivo e uso de ferramentas. Forte em detecção de inconsistência factual e verificação contra padrões conhecidos.
Pega: alucinação, falha lógica, premissa frágil
Arquitetura MoE com experts especializados por domínio. Forte em volume, paralelismo e em ângulos não-convencionais por roteamento de experts.
Pega: ângulos que Claude/GPT descartariam
🧪 O experimento mental
Imagine três Claudes Opus no Triad. Se Claude tem um viés sistemático contra X (ex: ângulos de negócio com risco regulatório), o Condutor não vai sugerir X, o Executor não vai gerar X, e o Crítico não vai detectar a ausência de X. O viés vira invisível para o sistema inteiro.
Agora misture: Opus condutor, DeepSeek executor (com experts diferentes), GPT-5.5 crítico (com RLHF diferente). A chance de todos os três compartilharem o mesmo viés cai drasticamente. O sistema vê o que cada modelo sozinho não veria.
💡 Analogia: revisão por pares
Em ciência, um paper de biologia revisto por três biólogos do mesmo grupo é mais frágil que o mesmo paper revisto por um biólogo, um estatístico e um físico. As cegueiras disciplinares são diferentes, e os erros que escapam de cada um são detectados pelos outros. O Triad aplica esse princípio a modelos de linguagem.
🔑 Conceitos-chave
Mesma arquitetura = mesmos vieses = mesmos pontos cegos
Constitutional AI + RLHF + MoE produz três tipos de visão diferentes
Os erros de cada modelo são detectados pelos pontos fortes dos outros
A justificativa científica do Triad — diversidade disciplinar reduz erro
🎯 Exemplo prático — escolha de nicho de negócio
Para tornar o fluxo concreto, vamos seguir uma execução real do início ao fim. O usuário envia uma pergunta vaga; o Triad devolve três nichos validados contra critérios mensuráveis. Cada passo do pipeline é mostrado.
O que é
Um walkthrough completo do Triad em ação, desde o pedido do usuário ("ajude a escolher um nicho de negócio") até a entrega final, passando pela interrogação do Condutor, briefing, exploração paralela do Executor, loop com o Crítico e validação final.
⏱️ Pipeline completo, passo a passo
"Me ajuda a escolher um nicho de negócio para abrir."
"Antes de despachar: (1) capital disponível? (2) tempo até precisar de receita? (3) localização? (4) está disposto a operar B2B ou só B2C? (5) tem alguma habilidade técnica que serve de barreira?"
"R$ 80k. 6 meses. Curitiba. B2B preferível. Sei programar e tenho 8 anos de experiência."
OBJETIVO: 3 nichos B2B em Curitiba com break-even < 6m
CRITÉRIOS:
- ticket médio ≥ R$ 3.000
- urgência alta (perda financeira em < 30 dias)
- ≥ 3 competidores identificados com preço
- barreira técnica que aproveite programação
- investimento inicial ≤ R$ 80k
RESTRIÇÕES: sem B2C; sem nicho saturado em Curitiba
ÂNGULOS: 1) automação fiscal · 2) compliance regulatório
3) integração de ERPs · 4) operação de e-commerce
Explora os 4 ângulos. Cada um com mercado endereçável, ticket estimado, 3 competidores, urgência e custo de aquisição. Total: ~12 páginas.
"Ângulo 1 OK. Ângulo 2 não documenta urgência ≥ 30d. Ângulo 3 cita competidores nacionais — restrição local não foi avaliada. Ângulo 4 viola restrição (e-commerce é B2C-adjacente em Curitiba)."
Ângulo 2 revisto (multa LGPD em 30d como gatilho). Ângulo 3 revisto (competidores locais Curitiba). Ângulo 4 descartado e substituído por "automação operacional para indústrias do CIC".
"Ângulos 1, 2, 3 atendem. Ângulo 4 ainda não documenta ticket ≥ R$ 3k — projetos de automação industrial geralmente são acima, mas o draft não cita fonte."
Ângulo 4 com ticket médio de R$ 8.500 documentado (3 cases públicos do CIC + Sebrae PR).
"Os 4 ângulos atendem aos 5 critérios. Encaminhar ao Condutor."
"Os 4 ângulos batem com o objetivo. Selecionando os 3 melhores (1, 3, 4) por melhor encaixe com 'programação como barreira' — o critério implícito do usuário. Entregando ranqueado."
3 nichos validados com ticket, urgência, competidores, barreira técnica e investimento — cada um defensável contra os critérios que o próprio usuário ajudou a definir.
🎯 O que mudou em relação a "pedir para um LLM"
Se o usuário tivesse perguntado a um único modelo "que nicho devo abrir?", a resposta seria plausível mas não verificada — sem critérios, sem comparação de ângulos, sem revisão por outra arquitetura. O Triad força que cada afirmação passe por um teste antes de chegar ao usuário.
🔑 Conceitos-chave
5 perguntas do Condutor eliminaram 80% da ambiguidade do pedido
Dentro do benchmark de complexidade média
O Crítico só aprova quando cada critério é demonstrado, não suposto
O Condutor não só valida — prioriza com base no contexto do usuário
✅ Resumo do Módulo
Próximo Módulo:
1.4 — soul.md, a memória persistente