✨ Por que DeepSeek V4 é diferente
DeepSeek V4 não é "mais um LLM barato". É um modelo open-weights de fronteira com arquitetura Mixture-of-Experts (MoE) que entrega desempenho comparável aos modelos proprietários top de linha, a uma fração do custo. Foi o modelo que provou que o oligopólio dos modelos fechados não era inevitável.
O que é
DeepSeek V4 é um modelo de linguagem open-weights desenvolvido pela DeepSeek (laboratório chinês de IA), com arquitetura MoE de 671B parâmetros totais e ~37B ativos por token. Foi treinado em corpora amplos de código, matemática e raciocínio, e seus pesos são publicamente disponíveis — qualquer um pode rodá-lo localmente ou via provedores de inferência.
🧬 A proposta única em quatro pilares
💡 Por que aprender
No Triad, o Worker é executado dezenas ou centenas de vezes por ciclo. Sem um modelo barato e capaz para esse papel, o sistema é economicamente inviável fora de casos de altíssimo valor. DeepSeek V4 transformou o Triad de "experimento caro" em "loop iterativo acessível".
🔑 Conceitos-chave
Pesos publicamente disponíveis — independência de um provedor único e competição de preço entre hosts
671B totais, ~37B ativos — qualidade de gigante com custo de médio
Provou que o estado-da-arte não precisa ser proprietário
Sem ele, loops iterativos como o Triad seriam inviáveis para a maioria
📊 Benchmarks comparativos — os números reais
Marketing de IA é cheio de declarações otimistas. Os benchmarks padronizados — MMLU, HumanEval, GSM8K, MATH, SWE-bench — são a única forma de comparar modelos com a mesma régua. Veja como DeepSeek V4 se posiciona contra os dois modelos de fronteira proprietários.
O que é
Benchmarks são suítes de tarefas padronizadas usadas para medir capacidades específicas dos modelos. MMLU avalia conhecimento multi-domínio, HumanEval mede geração de código, GSM8K e MATH avaliam raciocínio matemático, e SWE-bench testa correção de bugs reais em repositórios open-source.
| Benchmark | DeepSeek V4 | Claude Opus 4.7 | GPT-5.5 | Gap |
|---|---|---|---|---|
| MMLU (conhecimento geral) | 88.4% | 91.2% | 90.6% | −2.8 pp |
| HumanEval (código Python) | 90.1% | 94.5% | 93.0% | −4.4 pp |
| GSM8K (matemática básica) | 95.7% | 97.1% | 96.8% | −1.4 pp |
| MATH (matemática avançada) | 82.3% | 86.4% | 84.9% | −4.1 pp |
| SWE-bench (bugs reais) | 48.2% | 62.8% | 57.4% | −14.6 pp |
do nível do top proprietário em 4 de 5 benchmarks
gap médio nos benchmarks principais (excluindo SWE-bench)
mais barato por milhão de tokens que Opus 4.7
⚠️ Onde o gap importa
O único benchmark onde o gap é grande é SWE-bench (−14.6 pp vs Opus). Isso reflete que tarefas de engenharia complexas em código real ainda são domínio dos modelos premium. Para drafts, variações, geração paralela e raciocínio padrão, o gap é de 3–4 pontos percentuais — irrelevante quando o custo é 86× menor.
🔑 Conceitos-chave
A única forma confiável de comparar modelos com a mesma régua
Diferença típica entre DeepSeek V4 e top proprietários — irrelevante na maioria dos casos
Tarefas de engenharia complexa ainda favorecem modelos premium
−4 pp de qualidade por 86× menos custo é a melhor relação do mercado
🧮 95% do valor por 1% do preço — a aritmética
Esse não é um slogan de marketing. É uma conta literal que você pode refazer. Quando o custo cai 86× e a qualidade cai 4%, o ROI de usar DeepSeek V4 como executor não é incremental — é categórico.
O que é
A "aritmética 95×1" é o cálculo direto que mostra por que o trade-off de usar DeepSeek V4 no papel de executor é assimétrico — você troca uma fração marginal de qualidade por uma redução brutal de custo, viabilizando padrões de uso que com modelos premium seriam economicamente impossíveis.
📐 O cálculo, em monospace
# Cenário: tarefa que consome 10M tokens (input + output)
# Custo do trabalho
Opus 4.7 ........... 10M × $75/M = $750.00
GPT-5.5 ............ 10M × $40/M = $400.00
DeepSeek V4 ........ 10M × $0.87/M = $ 8.70
# Qualidade média (benchmarks normalizados)
Opus 4.7 ........... 100% (referência)
GPT-5.5 ............ 97%
DeepSeek V4 ........ 95%
# ROI de qualidade por dólar (vs Opus)
Opus 4.7 ........... 1.00× / 1.00× = 1.00× (baseline)
GPT-5.5 ............ 0.97× / 0.53× = 1.83×
DeepSeek V4 ........ 0.95× / 0.012× = 79× MELHOR
# Conclusão: −5% qualidade × 86× barato = 79× ROI
🎯 O que esse número desbloqueia
🔑 Conceitos-chave
Perde 5% de qualidade, ganha 86× em custo — assimetria categórica
79× mais valor por dólar gasto comparado ao baseline premium
Padrões de uso que eram inviáveis viram rotina
Você itera até convergir, não até estourar o orçamento
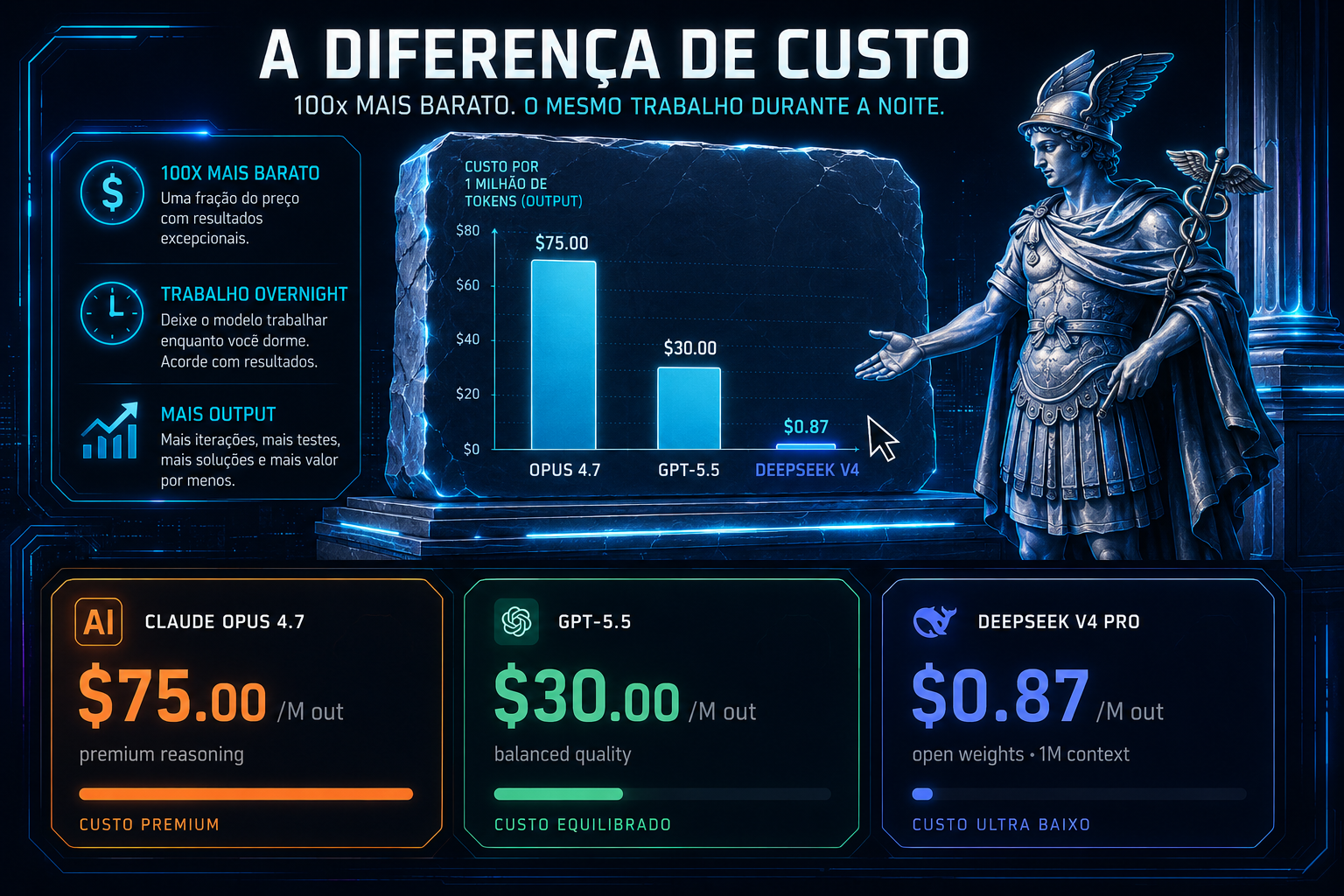
💲 $0,87 vs $75 por milhão de tokens
Olhar para o número agregado esconde o detalhe. Input e output têm preços diferentes, e modelos premium cobram desproporcionalmente caro pelo output. Veja a tabela completa.
O que é
A precificação por milhão de tokens (MTok) é a unidade padrão do mercado. Tipicamente o output é 3–5× mais caro que o input, refletindo o custo computacional adicional da geração autoregressiva. A relação input/output dominante na sua aplicação determina qual modelo é economicamente viável.
| Modelo | Input ($/MTok) | Output ($/MTok) | Blended* | vs DeepSeek |
|---|---|---|---|---|
| Claude Opus 4.7 | $15.00 | $75.00 | $30.00 | 86× |
| GPT-5.5 | $10.00 | $40.00 | $17.50 | 50× |
| Claude Sonnet 4.6 | $3.00 | $15.00 | $6.00 | 17× |
| GPT-5.5 mini | $1.50 | $6.00 | $2.63 | 7.5× |
| DeepSeek V4 | $0.27 | $1.10 | $0.87 | 1× |
* Blended assume relação típica input:output de 3:1.
💰 Cenário: 1 milhão de drafts curtos
- 500 tokens input, 1.500 tokens output cada
- Volume total: 2B tokens (0.5B in + 1.5B out)
- Opus 4.7: $120.000
- GPT-5.5: $65.000
- Sonnet 4.6: $24.000
- DeepSeek V4: $1.785
🌙 Cenário: loop noturno de 8 horas
- ~120M tokens processados (mix in/out)
- Worker rodando 24 iterações por ângulo
- Opus 4.7: $3.600
- GPT-5.5: $2.100
- Sonnet 4.6: $720
- DeepSeek V4: $104
📌 O detalhe que importa
Output é 4× mais caro que input em quase todos os modelos. Como o Worker gera muito mais do que consome, é o output que domina a fatura. DeepSeek V4 cobra $1,10 por milhão de tokens de output — o que torna geração intensiva de drafts economicamente trivial pela primeira vez na história desse mercado.
🌙 Por que barato significa "executar por horas sem culpa"
Há uma diferença psicológica enorme entre uma ferramenta que você usa com calculadora ao lado e uma que você pode deixar rodar a noite toda sem pensar. Essa diferença muda o que você se permite experimentar.
O que é
A "libertação psicológica do custo" é a mudança de comportamento que acontece quando o preço de uma operação cai abaixo do limiar de atenção do usuário. Quando você não precisa mais decidir "vale a pena rodar isso?", você roda tudo — e o volume de experimentação dispara.
🧠 O efeito "abaixo do limiar de atenção"
Com modelo caro ($30/MTok):
Cada execução tem um custo psicológico antes do financeiro. Você pondera, hesita, simplifica o prompt para economizar, restringe ângulos paralelos. O sistema fica subutilizado por medo do extrato.
Com DeepSeek V4 ($0,87/MTok):
Cada execução custa menos que um café. Você roda 50 vezes antes do almoço sem registrar. O loop deixa de ser um recurso escasso e vira utilitário — como CPU local.
22:00 — você dispara o loop
Briefing entregue ao Condutor. Worker programado para 5 ângulos × 30 iterações máximas cada. Custo projetado: ~$80. Você fecha o laptop.
02:00 — o loop está iterando
Crítico já reprovou 14 drafts. Worker está no terceiro ângulo, inverteu duas premissas. A máquina trabalha. Você dorme.
07:00 — você revisa o resultado
3 ângulos com SHIP, 2 com FUNDAMENTAL FLAW e justificativa. Custo real: $73. Você gastou em uma noite de exploração o que com Opus pagaria por 30 minutos.
💡 Mão-de-obra barata = mais experimentação
Cada redução de 10× no custo de uma operação muda o que as pessoas fazem com ela. DeepSeek V4 caiu quase 100× — não é otimização incremental, é mudança de categoria. Você passa de "vou usar quando for importante" para "vou usar para qualquer coisa".
🎯 A regra dos 5 dólares
Quando uma operação custa menos de $5, ela some da sua cognição de custo. Você executa pelo valor que pode gerar, não pelo preço de rodar. DeepSeek V4 colocou ciclos completos de Triad abaixo desse limiar.
🎯 Casos onde DeepSeek V4 brilha e onde não usar
Adotar DeepSeek V4 sem critério é tão ruim quanto evitar por reflexo. A regra é simples: use-o para volume e exploração; reserve os premium para decisão final e raciocínio de fronteira.
✓ Onde DeepSeek V4 brilha
- ✓Geração de código — funções, scaffolds, refactors de complexidade média. HumanEval em 90%.
- ✓Drafts e rascunhos — primeiras versões a serem refinadas. Volume sem culpa.
- ✓Sumarização de pesquisa — sintetizar 30 fontes em 2 páginas. Tarefa repetitiva, padronizada.
- ✓Variações de conteúdo — 20 títulos, 10 ledes, 5 ângulos. Diversidade pelo volume.
- ✓Exploração paralela — múltiplos ângulos do mesmo problema. Premissa diferente sem custo proibitivo.
- ✓Classificação e extração — rotular dados, extrair entidades. Tarefa estruturada onde 95% basta.
✗ Onde não usar (use premium)
- ✗Decisão final estratégica — a chamada que importa. Os 5% de qualidade pesam aqui.
- ✗Conteúdo de cara para o cliente sem revisão — risco de erro sutil que escapa em escala.
- ✗Raciocínio ultra-novel — problemas de fronteira onde a borda do estado-da-arte importa.
- ✗Bugs reais em código complexo — SWE-bench mostra gap de 14 pontos. Reserve Opus.
- ✗O papel de Crítico — discriminação fina entre bom e ótimo precisa do modelo mais capaz.
- ✗Negociação ou raciocínio adversarial — onde nuances de prompt-injection ou estratégia importam.
⚖️ A heurística de roteamento
🔑 Conceitos-chave
DeepSeek para volume; premium para a chamada final que importa
Se há revisão downstream, os 5% de gap são absorvidos sem custo real
Gap de 14 pp indica zonas onde os premium ainda dominam
Quando em dúvida, rode os dois — a diferença de custo permite
⚙️ DeepSeek V4 no fluxo Triad — o papel de executor
No Triad, cada modelo tem um papel específico. DeepSeek V4 é o Worker (Executor) — o motor que produz volume, gera ângulos paralelos e responde aos pedidos de revisão do Crítico. Opus brieda, GPT critica, DeepSeek executa.
O que é
No Triad, o papel de Worker é o consumidor dominante de tokens — é ele quem gera drafts, explora ângulos paralelos e refaz o trabalho a cada iteração do loop. Usar DeepSeek V4 nesse papel é o que torna o sistema economicamente viável. Os papéis de Condutor (Opus) e Crítico (GPT) são executados poucas vezes por ciclo e podem custear modelos premium.
🎭 A divisão de papéis e custos no Triad
| Papel | Modelo | Frequência por ciclo | % do custo total |
|---|---|---|---|
| Condutor (briefing + validação final) | Claude Opus 4.7 | 2 chamadas | ~30% |
| Worker (executor de drafts) | DeepSeek V4 | 15–40 chamadas | ~15% |
| Crítico (SHIP/REVISE) | GPT-5.5 | 10–30 chamadas | ~55% |
Observe: o Worker faz 15–40 chamadas, mas responde por apenas ~15% do custo total — porque DeepSeek V4 é 50–86× mais barato. Sem ele, Worker seria 60% da fatura.
Passo 1 — Condutor (Opus): ~$0,45
15K tokens de briefing detalhado. Custo único, mas pesado por token. O briefing precisa ser preciso para guiar tudo que vem depois.
Passo 2 — Worker (DeepSeek V4) × 25: ~$0,22
25 chamadas de ~10K tokens cada (250K total). Gera 5 ângulos, refaz 20 vezes em resposta ao Crítico. Esse seria o ponto de ruptura econômica sem DeepSeek.
Passo 3 — Crítico (GPT-5.5) × 22: ~$0,82
22 chamadas de ~8K tokens. Discriminação fina entre drafts. Usa modelo premium porque a qualidade da crítica define se o loop converge.
Passo 4 — Validação final pelo Condutor: ~$0,15
Opus revisa o output finalista contra o briefing original. Última checagem antes da entrega ao usuário.
💰 Total de 1 ciclo Triad: ~$1,64
Esse mesmo ciclo, com Opus em todos os três papéis, custaria ~$22,50. A escolha de DeepSeek V4 no papel de Worker é o que move o sistema de "experiência cara" para "rotina diária". É o componente que viabiliza o restante.
🔑 Conceitos-chave
Maior frequência por ciclo, executor de drafts e variações — o consumidor de volume
Cada modelo onde melhor entrega valor por dólar dentro da sua função
Custo típico de um ciclo Triad bem configurado — abaixo do limiar de atenção
Sem DeepSeek V4, o loop Worker-Crítico seria proibitivamente caro
🎓 Resumo do Módulo — e da Trilha 1
Este foi o último módulo da Trilha 1. Você terminou os fundamentos: o problema do AI slop, a tese Triad, e os três modelos que compõem a arquitetura — Claude Opus 4.7 (Condutor), GPT-5.5 (Crítico) e DeepSeek V4 (Executor).
Próxima Trilha:
Trilha 2 — Implementação Técnica do Hermes + Triad. Você aprendeu o porquê. Agora vamos para o como.