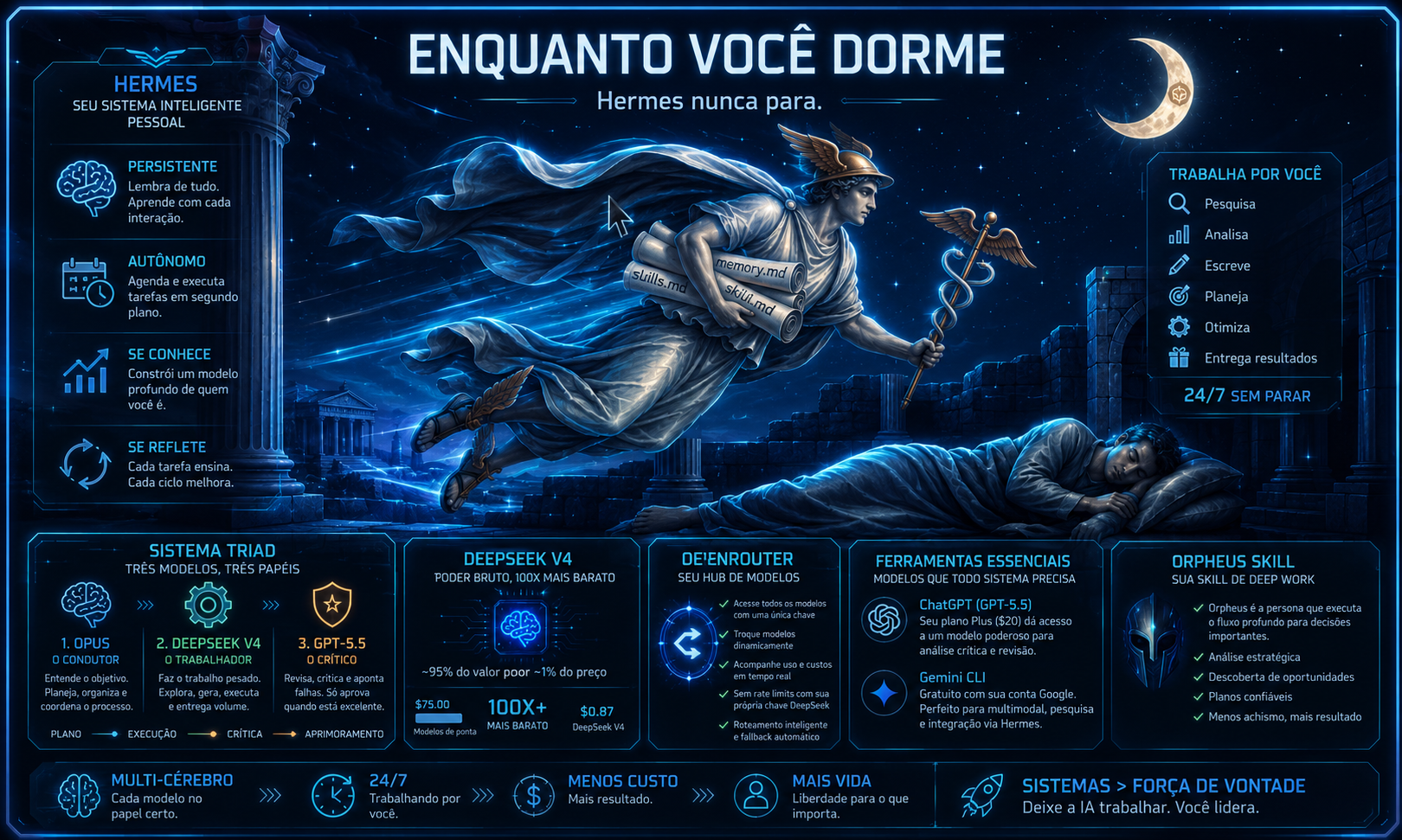
🌙 O que pode ser feito enquanto você dorme
Toda noite são 8 horas de capacidade computacional desperdiçadas se você não programa nada. O Triad foi construído para esse turno — tarefas longas que precisam de paralelismo, iteração e crítica, mas não precisam de você no loop.
O que é
Automação overnight é o uso da janela noturna (22h–6h tipicamente) para rodar tarefas Triad que consomem horas de loop Worker-Crítico e seriam impraticáveis durante o trabalho síncrono. Pesquisa profunda, varreduras de mercado, revisões de código em lote e geração de conteúdo em batch são candidatos naturais.
📋 Quatro categorias de trabalho overnight
✓ Boa tarefa overnight
- ✓Critérios de sucesso testáveis e fechados
- ✓Não exige decisão humana no meio
- ✓Falha parcial ainda gera valor (5 de 12 análises = útil)
- ✓Saída inspecionável de manhã em <15min
✗ Má tarefa overnight
- ✗Requer aprovação intermediária do usuário
- ✗Critério de sucesso depende de contexto vivo
- ✗Output enorme que você não vai revisar
- ✗Sem fallback se uma API externa cair
💡 Por que aprender
A janela overnight dobra sua capacidade efetiva sem dobrar seu custo cognitivo. Quem domina jobs agendados produz em uma semana o que outros produzem em um mês — porque o trabalho continua quando o operador para.
🔑 Conceitos-chave
22h–6h como turno computacional dedicado a tarefas longas
Critérios fechados, sem necessidade de decisão humana no meio
Mesmo se incompleta, a tarefa ainda entrega valor verificável
8h de loop noturno ≈ 1 dia adicional de trabalho por dia
⏰ Configurando jobs recorrentes no Hermes
O Hermes expõe um agendador interno baseado em cron. A sintaxe é padrão Unix — minuto, hora, dia do mês, mês, dia da semana — e cada job recebe um nome para que você possa consultar histórico e logs depois.
O que é
O comando hermes schedule registra um job recorrente que dispara um comando Triad em horários definidos por expressão cron. O Hermes mantém o registro em ~/.hermes/schedule.db e o dispatcher dorme no background até o próximo trigger.
⚙️ Comandos essenciais
$ hermes schedule add \
--name=overnight-research \
--cron="0 22 * * *" \
--command='hermes run job:research --topic="competitive landscape"'
$ hermes schedule add --name=morning-briefing --at="06:00" --command="hermes briefing"
$ hermes schedule list
$ hermes schedule pause overnight-research
$ hermes schedule remove overnight-research
🕐 Sintaxe cron — referência rápida
┌─ minuto (0–59)
│ ┌─ hora (0–23)
│ │ ┌─ dia do mês (1–31)
│ │ │ ┌─ mês (1–12)
│ │ │ │ ┌─ dia da semana (0–6, dom=0)
* * * * * <comando>
0 22 * * * todo dia às 22h
0 22 * * 1-5 seg–sex às 22h
0 */4 * * * a cada 4 horas
30 23 * * 0 domingo 23h30
💡 Dica de horário
Distribua jobs em horários diferentes (22h, 23h, 1h, 3h) em vez de tudo às 22h. Evita pico de uso de API simultâneo, contorna rate limits e dá margem para retries sem competir consigo mesmo.
🔑 Conceitos-chave
Comando primário para registrar job recorrente com nome e cron expression
Identificador estável usado em logs, histórico, pause/remove e checkpoints
Espaçar jobs evita pico de rate limit e competição entre tarefas próprias
Persistência local em ~/.hermes — sobrevive a reinicializações da máquina
📥 Definindo entradas e saídas esperadas
Job overnight sem contrato explícito de entrada/saída é uma caixa-preta — você acorda sem saber o que esperar. O manifesto YAML torna o contrato visível, versionável e auditável pelo Crítico antes da execução.
O que é
Um job manifest é um arquivo YAML em ~/.hermes/jobs/<nome>.yaml que declara o nome do job, horário de execução, entradas esperadas (com tipos), saídas garantidas (com formato), frequência de checkpoint e política de retry. O Hermes carrega esse manifesto a cada execução.
📄 Exemplo: overnight-research.yaml
name: overnight-research
runs_at: "0 22 * * *"
timeout: 8h
inputs:
topic: string # obrigatório
depth: enum[shallow,medium,deep]
sources: list[url]
outputs:
format: markdown
path: "~/triad-out/research/{date}-{topic}.md"
min_sections: 5
required_fields: [summary, angles, sources, confidence]
checkpoint_every: 15min
retry_on_failure:
max_attempts: 3
backoff: exponential
📋 Anatomia do manifesto
manual para gatilho sob demanda.required_fields como gate antes de SHIP.🔑 Conceitos-chave
Contrato declarativo do job — versionável no git, auditável antes da execução
Validação antes do Worker — input inválido falha cedo, não no meio da noite
Gate objetivo do Crítico — sem todos os campos, não emite SHIP
Validação no início economiza horas de execução desperdiçada
💾 Gerenciando memória para tarefas longas — checkpoints
Tarefa de 6 horas que falha na quinta hora sem checkpoint = 5 horas perdidas. Checkpoints transformam falha catastrófica em retomada barata — o Hermes grava estado intermediário em disco e o Worker pode continuar do último ponto válido.
O que é
Um checkpoint é um snapshot JSON do progresso do job — qual ângulo já foi processado, qual output parcial foi acumulado, qual decisão do Crítico está pendente — gravado em ~/.hermes/jobs/<nome>.checkpoint.json a cada intervalo definido no manifesto.
📦 Exemplo de checkpoint
# ~/.hermes/jobs/overnight-research.checkpoint.json
{
"job": "overnight-research",
"started_at": "2026-05-17T22:00:14Z",
"last_checkpoint_at": "2026-05-18T01:45:02Z",
"angles_total": 5,
"last_completed_angle": 3,
"current_angle": {
"index": 4,
"phase": "worker_drafting",
"iteration": 2
},
"partial_output": "~/triad-out/research/.partial-2026-05-17.md",
"tokens_consumed": 142300,
"resume_token": "ckpt_a8f3e91c"
}
✗ Sem checkpoint
- ✗API cai às 4h → 6h de trabalho perdidas
- ✗Manhã: arquivo de output vazio, sem pistas
- ✗Retry recomeça do zero — gasta tokens duas vezes
- ✗Impossível diagnosticar onde falhou
✓ Com checkpoint a cada 15min
- ✓API cai às 4h → no máximo 15min perdidos
- ✓Manhã: ângulos 1–3 prontos, partial em disco
- ✓
hermes resumeretoma do último checkpoint - ✓Log mostra exatamente em que fase quebrou
⚙️ Retomada após falha
$ hermes job status overnight-research
$ hermes job resume overnight-research
$ hermes job restart overnight-research --fresh
💡 Regra prática
Checkpoint a cada 15min para jobs <2h. A cada 5–10min para jobs longos. O custo é baixo (alguns KB em disco); o retorno em caso de falha é uma noite inteira preservada.
🔑 Conceitos-chave
JSON do progresso gravado em disco a cada N minutos
Identificador opaco que o Worker usa para retomar exatamente onde parou
Retomada barata vs restart caro — preserva tokens já gastos
Checkpoint converte perda total em perda do último intervalo
☀️ Revisão matinal — o protocolo hermes morning
Não basta rodar a noite — você precisa ter um protocolo de manhã que decide rapidamente: o que vai pra produção, o que precisa de iteração, o que descarta. 15 minutos por dia mantém o sistema rodando bem.
O que é
O comando hermes morning agrega o resultado de todos os jobs overnight em um resumo único — quais terminaram SHIP, quais terminaram em PARTIAL_DELIVERY, quais falharam, quais campos o Crítico flagou para revisão humana. Foi pensado para ser o primeiro comando do dia.
🌅 Output típico do hermes morning
$ hermes morning
━━━ Resumo da noite (2026-05-17 22:00 → 06:00) ━━━
✓ SHIP overnight-research (4h 12m, 3 iterações)
→ ~/triad-out/research/2026-05-17-competitive-landscape.md
✓ SHIP market-scan (1h 03m, 1 iteração)
→ 4 mudanças de preço detectadas
⚠ PARTIAL code-review-batch (5/8 módulos)
motivo: rate limit às 03:42, retomavel
✗ FLAGGED content-batch (precisa revisão humana)
Crítico: "premissa do ângulo 2 não verificável"
━━━ Ação sugerida ━━━
1. revisar content-batch (5 min)
2. hermes job resume code-review-batch
3. publicar overnight-research e market-scan
⏱️ Timeline da revisão matinal — 15 minutos
Trigger — rodar hermes morning assim que abre o terminal. Visão geral em 30 segundos.
Triagem — separar SHIP (publica), PARTIAL (retomar), FLAGGED (revisar agora). Decisão binária por item.
Inspeção dos FLAGGED — abrir cada item flagueado, ler o motivo do Crítico, decidir: corrigir prompt ou aceitar com edit manual.
Resume e ajuste — disparar hermes job resume nos PARTIAL, ajustar manifesto se o mesmo flag se repete há 3 dias.
⚠️ Sinal de alerta
Se a revisão matinal está consumindo mais de 30 minutos por dia, seus critérios de sucesso estão frouxos demais — o Crítico está deixando passar trabalho que deveria ter sido reprovado no loop noturno. Ajuste o manifesto.
🔑 Conceitos-chave
Comando único que agrega resultados da noite com ações sugeridas
SHIP (publica), PARTIAL (retoma), FLAGGED (revisa)
Acima disso, o sistema está empurrando ruído para revisão humana
Mesmo flag 3 dias seguidos → corrigir manifesto, não corrigir o output
🔗 Combinando Hermes com N8N para automações externas
O Hermes lida bem com o que vive na sua máquina. O N8N é a ponte para o mundo externo — webhooks, APIs SaaS, sheets, e-mail, Slack. A combinação faz o Triad reagir a eventos do mundo real, não só ao relógio.
O que é
N8N é uma plataforma de automação visual que orquestra integrações externas. Você pode chamar o Hermes a partir do N8N via webhook — útil quando o trigger não é horário (cron) mas sim um evento (e-mail chegou, planilha mudou, deploy terminou).
🌉 Padrão: N8N → Hermes via webhook
# 1. expor o Hermes localmente
$ hermes webhook serve --port=7842 --token=$HERMES_TOKEN
# 2. no N8N, criar fluxo:
# Trigger (Gmail/Schedule/Webhook) → HTTP Request
# 3. o nó HTTP Request chama:
POST http://localhost:7842/jobs/run
Headers: Authorization: Bearer $HERMES_TOKEN
Body: {
"job": "on-demand-research",
"inputs": { "topic": "{{$json.subject}}" }
}
🎯 Quando usar N8N vs hermes schedule
hermes schedule
- • Trigger é horário fixo (cron)
- • Job vive 100% local
- • Sem dependência de SaaS externo
- • Ex: research diário às 22h
N8N → Hermes
- • Trigger é evento externo
- • Precisa coletar inputs de APIs
- • Saída precisa ir para Slack/Notion
- • Ex: novo lead → dossiê automático
🔒 Segurança do webhook
Sempre exija token Bearer e rode o webhook em localhost ou via túnel autenticado (Tailscale, Cloudflare Tunnel). Webhook do Hermes exposto sem auth é vetor de execução remota.
🔑 Conceitos-chave
Endpoint HTTP local que dispara jobs sob demanda
Coleta triggers do mundo, normaliza payload, chama Hermes
Cron para o que repete; webhook para o que reage
Webhook sem auth = porta aberta para execução remota
🔁 Criando um loop de melhoria contínua
O nível mais alto da automação overnight: o Triad iterando sobre o output anterior do próprio Triad. Cada noite o sistema lê o que produziu antes, critica, e produz uma versão melhor. Composição de loops em escala de dias.
O que é
Um loop de melhoria contínua é um job overnight cujo input é o output da noite anterior. O Condutor formula um briefing de "como melhorar o draft de ontem"; o Worker propõe melhorias; o Crítico aplica SHIP/REVISE. Após 5–7 ciclos, a saída converge para algo significativamente superior à versão inicial.
♾️ O ciclo de uma noite
~/triad-out/iter/draft-N.md mais o log de críticas acumuladas das noites passadas.draft-(N+1).md, regressão de critérios já passados.~/triad-out/iter/log.jsonl com diff de qualidade e novos pontos fracos identificados.📄 Manifesto do loop iterativo
name: continuous-improvement
runs_at: "0 22 * * *"
inputs:
previous_draft: "~/triad-out/iter/draft-latest.md"
critique_history: "~/triad-out/iter/log.jsonl"
max_iterations: 7 # para automaticamente
outputs:
next_draft: "~/triad-out/iter/draft-{N+1}.md"
improvement_diff: "~/triad-out/iter/diff-{N+1}.md"
stop_conditions:
- "no_new_critiques_for_2_iterations"
- "max_iterations_reached"
🛑 Saiba parar o loop
Loops infinitos viram desperdício. Use stop_conditions claros: número máximo de iterações, ausência de novas críticas por 2 ciclos, custo cumulativo acima de um teto. Sem parada, o sistema gira mesmo quando já convergiu.
🔑 Conceitos-chave
Cada noite consome o draft da noite anterior e produz uma versão melhor
Log acumulado das críticas — o Condutor usa para priorizar próximos ataques
Critérios objetivos para encerrar o loop quando ele converge
Tempo típico até o sistema deixar de produzir críticas novas
✅ Resumo do Módulo
Próximo Módulo:
4.4 — Integrações: conectando o Triad ao resto do seu stack